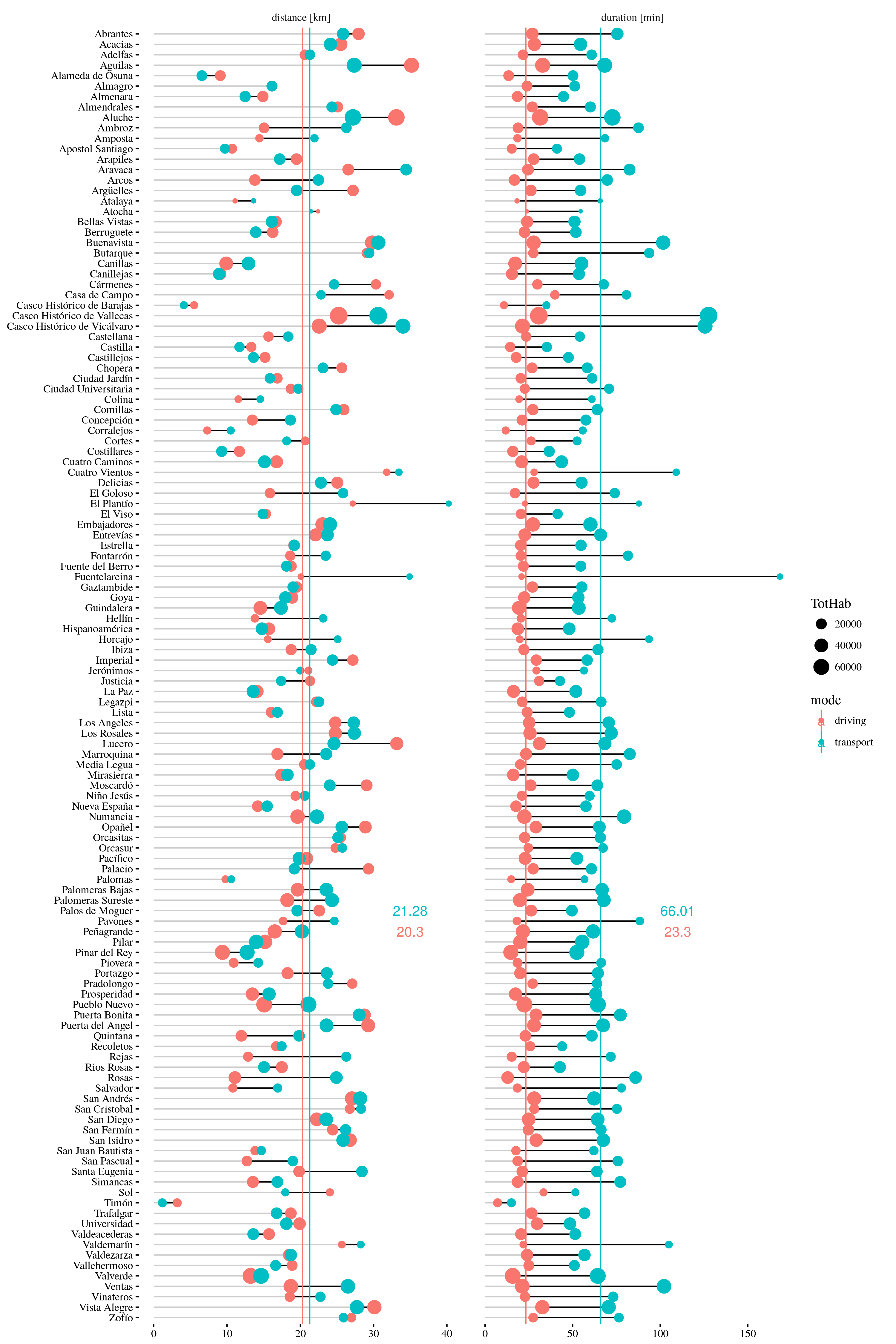
Por sugerencia de Almudena, continúo el artículo de ayer, De la T4 a Madrid: ¿coche o transporte público?, con otra gráfica interesante: el tiempo de viaje vs. la distancia al aeropuerto. Del mismo modo que en dicho artículo, cada punto representa un barrio, con el tamaño del punto proporcional a su población. Además, las regresiones están ponderadas por población.
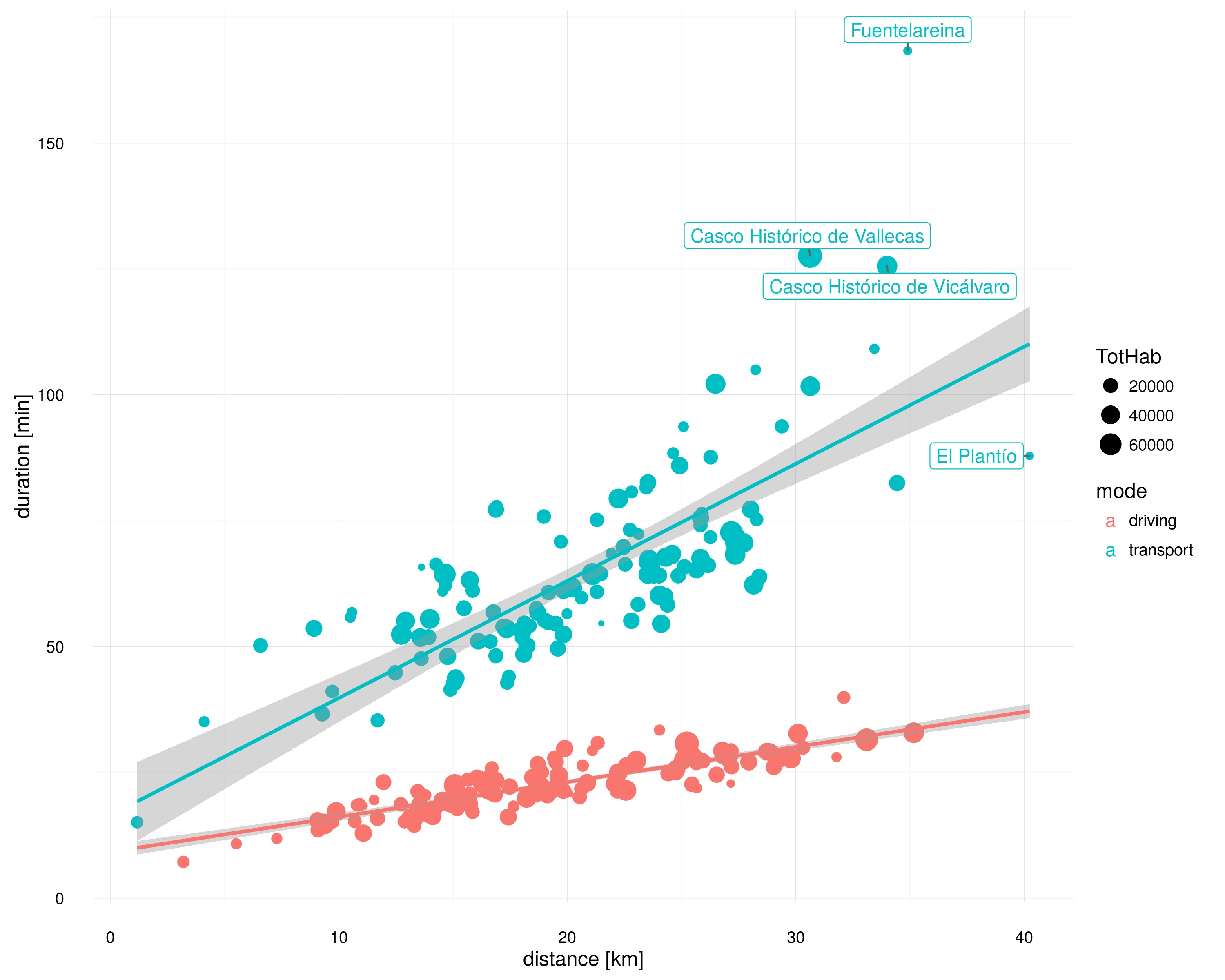
La información que nos proporciona es qué barrios están mejor o peor comunicados. En principio, esperamos que el tiempo aumente proporcionalmente con la distancia, como ocurre en el caso del viaje en coche. En el caso del transporte público, la pendiente es mayor, por lo que un aumento de distancia penaliza más en tiempo, cosa que también es razonable.
Pero además hay puntos concretos que se alejan sustancialmente de la línea por abajo (lo que significa que están especialmente bien comunicados) o por arriba (lo que significa que están especialmente mal comunicados). En la primera categoría, destaca El Plantío, un pequeño barrio del distrito de Moncloa-Aravaca que es el más lejano de Madrid, pero se encuentra especialmente bien comunicado. En la segunda categoría, destacan Fuentelareina, Vicálvaro y Vallecas. El primero tiene poca población, pero Vicálvaro y Vallecas son dos de los barrios más grandes de Madrid, y sin embargo cuentan, comparativamente, con las peores conexiones en transporte público con la terminal T4.
Actualización
Me comentan por Twitter que la conexión desde Vallecas no es tan mala. Efectivamente, una consulta a mano desde zonas razonables del barrio arroja tiempos más bajos. Compruebo en los mapas de Madrid que el territorio del barrio Casco Histórico de Vallecas es bastante amplio, pero la zona urbanizada está apelotonada en el norte y este de la zona.
Dado que los cálculos se han hecho automáticamente a partir del centroide del barrio, esto con toda probabilidad ha hecho que se sobrestimen los tiempos en barrios con una geografía poco homogénea como Vallecas. Las conclusiones, en tales casos, son erróneas.
Una mejora sencilla al método del centroide consistiría en dividir cada barrio en una rejilla de puntos, hacer los cálculos para cada punto y después descartar a partir de cierto umbral. Esto tampoco está exento de problemas, ya que podría haber un barrio con más zona sin urbanizar que urbanizada, por lo que los outliers serían los tiempos reales.
Otra mejora aún más sencilla (y rápida) consiste en dejar a Google Maps decidir dónde está «Casco Histórico de Vallecas» (que parece que no lo hace mal), y así con todos los barrios. Esto es lo que ha hecho Marco rápidamente, me ha pasado los datos y los resultados cambian sustancialmente para la gráfica anterior:
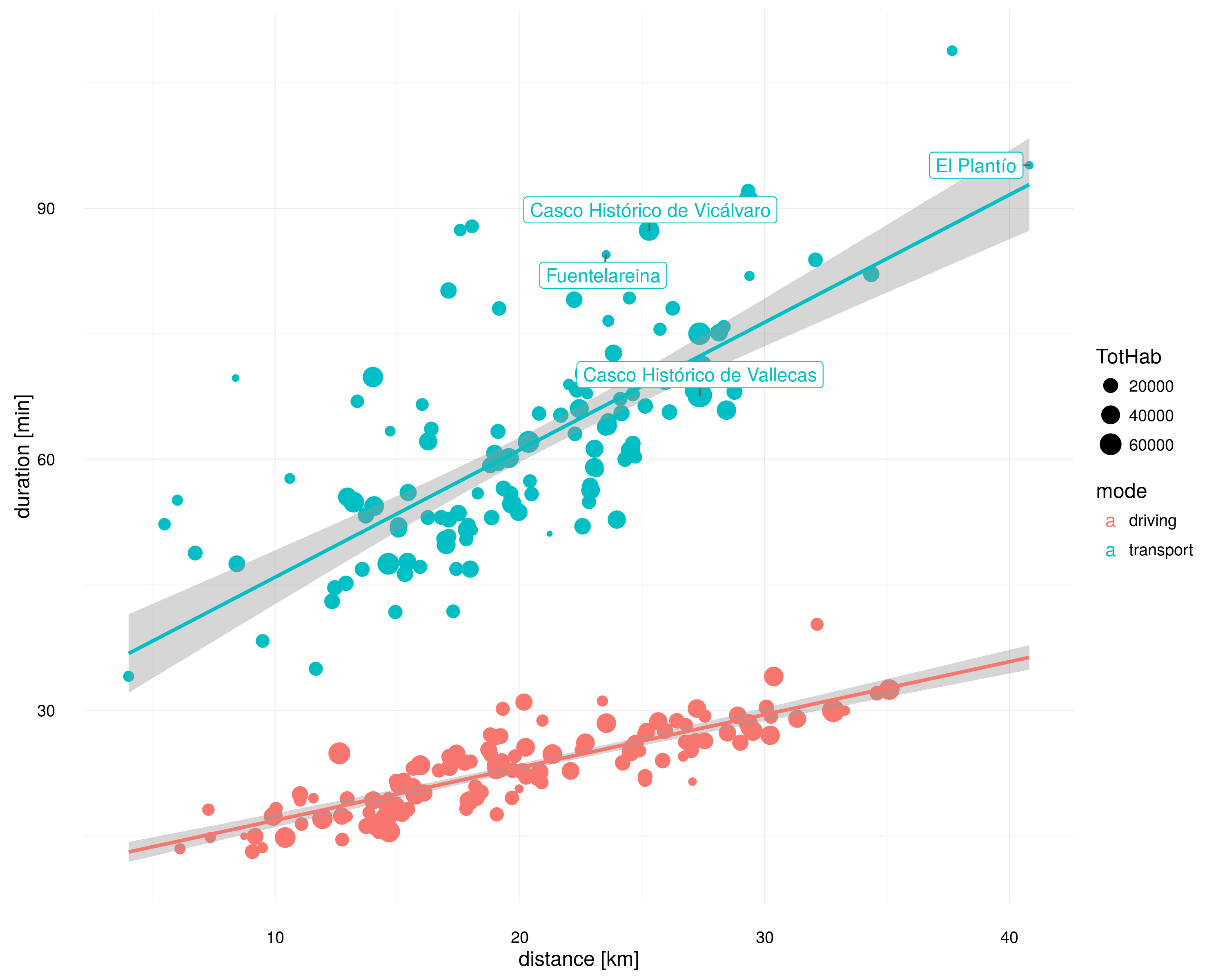
Buenas noticias: El Plantío ya no aparece como favorecido ni Vallecas como desfavorecido. Fuentelareina y Vicálvaro por su parte sí siguen situándose por encima de la tendencia generalizada. Quedaría actualizar la gráfica del artículo anterior, pero adelanto que las medias para todo Madrid se ven poco afectadas.