R objects are documented in files written in “R documentation” (Rd) format, a simple markup language much of which closely resembles (La)TeX, which can be processed into a variety of formats, including LaTeX, HTML and plain text.
This LaTeX-like syntax, combined with the fact that the actual R objects live in a separate place, feels burdensome for many developers. As a consequence, there are a handful of tools aimed at improving the documentation process, one of which is roxygen2. We may say that the R community nowadays is divided between those who use roxygen2 and those who don’t.
The roxygen2 package allows us to write documentation right next to the code that is being described with decorated comments. The advantages are the following:
- Code and documentation are adjacent so when you modify your code, it’s easy to remember that you need to update the documentation.
- Roxygen2 dynamically inspects the objects that it’s documenting, so it can automatically add data that you’d otherwise have to write by hand.
- It abstracts over the differences in documenting S3 and S4 methods, generics and classes so you need to learn fewer details.
Although both roxygenists and non-roxygenists surely agree that documentation is one of the most important aspects of good code, the alleged benefits of roxygen2 could turn into a disadvantage. In the words of Duncan Murdoch,
This isn’t the fashionable point of view, but I think it is easier to get good documentation [by directly editing Rd files] than using Roxygen. […]
The reason I think this is that good documentation requires work and thought. You need to think about the markup that will get your point across, you need to think about putting together good examples, etc. This is harder in Roxygen than if you are writing Rd files, because Roxygen is a thin front end to produce Rd files from comments in your .R files. To get good stuff in the help page, you need just as much work as in writing the .Rd file directly, but then you need to add another layer on top to put in in a comment. Most people don’t bother.
Basically, roxygen2’s point is that you don’t need to work in the syntax, so that you can use that time to write actual documentation. Duncan’s point, instead, is that, if you don’t put effort in the writing process, there’s a chance that you won’t put any effort at all. Although I’m a happy roxygen2 user, I can see there’s a point in there, and an interesting analysis to be done.
In fact, if you happen to have an uncompressed copy of CRAN under, let’s say, ~/cran, you can execute the following script:
## Requires: r-lib/pkgdown, readr
setwd("~/cran")
get_lines <- function(Rd) {
# render as txt
txt <- try(capture.output(tools::Rd2txt(Rd)), silent=TRUE)
if (inherits(txt, "try-error")) # "rcqp" throws an error, why?
return(c(documentation=NA, examples=NA))
# remove blank lines
txt <- txt[!grepl("^[[:space:]]*$", txt)]
# split documentation and examples
examples <- grep("_\bE_\bx_\ba_\bm_\bp_\bl_\be_\bs:", txt)
if (length(examples)) {
doc <- txt[1:(examples-1)]
exm <- txt[(examples+1):length(txt)]
} else {
doc <- txt
exm <- NULL
}
# remove titles
doc <- doc[!grepl("_\b", doc)]
# output
c(documentation=length(doc), examples=length(exm))
}
do.call(rbind, parallel::mclapply(Sys.glob("*"), function(pkg) {
message("Parsing ", pkg, "...")
rds <- Sys.glob(file.path(pkg, "man", "*.[R|r]d"))
if (!length(rds))
df <- data.frame(documentation=0, examples=0, functions=0)
else {
# get no. lines for documentation & examples
df <- as.data.frame(t(rowSums(sapply(rds, get_lines), na.rm=TRUE)))
# get no. exported functions
df$functions <- sum(sapply(rds, function(rd) {
rd <- pkgdown:::rd_file(rd)
length(pkgdown:::usage_funs(pkgdown:::topic_usage(rd)))
}))
}
# RoxygenNote present?
desc <- file.path(pkg, "DESCRIPTION")
df$roxygen <- !is.na(read.dcf(desc, fields="RoxygenNote")[[1]])
df$pkg <- pkg
df
}, mc.cores=parallel::detectCores())) -> docLines
readr::write_csv(docLines, "docLines.csv")to get this data frame. For each package on CRAN, we extract the number of lines of documentation and examples under the man directory, as rendered by tools::Rd2txt. We also count how many functions are documented, and we scan the DESCRIPTION file looking for the RoxygenNote, to tell which packages use roxygen2. This is all I need to see what I was looking for:
library(ggplot2)
library(dplyr)
library(tidyr)
docLines <- read.csv("docLines.csv") %>%
filter(functions > 0) %>%
gather("type", "lines", documentation, examples)
ggplot(docLines, aes(lines/functions, color=roxygen, fill=roxygen)) + theme_bw() +
geom_density(alpha=.3) + facet_wrap(~type) + scale_x_log10()## Warning: Transformation introduced infinite values in continuous x-axis## Warning: Removed 221 rows containing non-finite values (stat_density).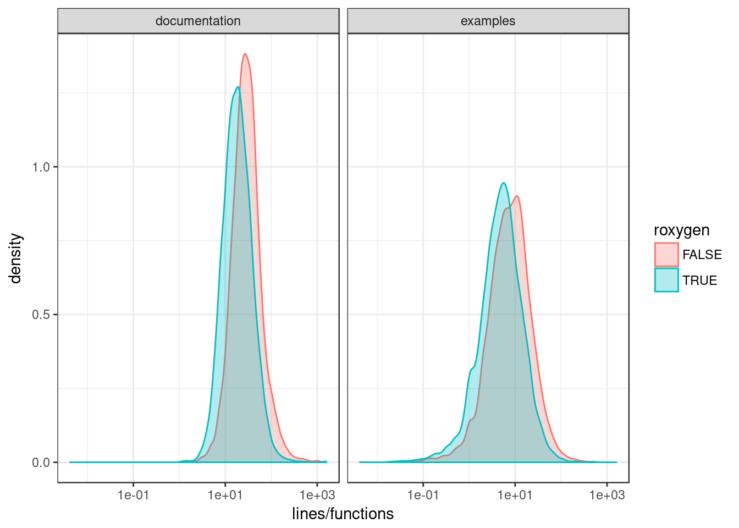
Limitations:
- This talks about quantity, but not about quality.
- The method of extraction of documentation and examples is very coarse. For sure there are better ways.
- The amount of documentation must be weighted in some way. Just dividing it by the number of exported functions and methods may not be the best way.
roxygen2appeared in 2011, but I think it became more popular in recent years. It may be interesting to restrict the analysis to recent packages.- Some developers prioritise vignettes over examples. It may be another interesting factor to analyse.
But all in all, I believe that this simple analysis proves Duncan right to some extent. And as a roxygen2 user that very much cares about documentation, this warns me against my own biases. If you care too, make sure that you really take advantage of the time you save with roxygen2.
[…] article was first published on R – Enchufa2, and kindly contributed to […]
[…] Article originally published in Enchufa2.es: Documenting R packages: roxygen2 vs. direct Rd input. […]
[…] Article originally published in Enchufa2.es: Documenting R packages: roxygen2 vs. direct Rd input. […]
Nice analysis. I’d like to see some more focused questions. There are plenty of instances where a dataset is provided with barely any description.
I don’t think I can give up roxygen2. I’ve only written one package before using roxygen and R Studio’s build tools, and the mental scars remain to this day. But I know for a fact my documentation’s been slipping in quality ever since using roxygen.
When you think about it, the internet (especially GitHub) means there are a lot of potential users for our packages, but they’ll only use what they understand. So adding one line of documentation could add more value than 10 new features.
Me too! There is a lot of potential fun by playing with these data and the output from
tools::CRAN_package_db(). If I had time… ;-)Agreed. And I particularly care about vignettes. That’s the first thing I look for when I start using a new package.